
The $4.6 trillion AI economy runs on a single decision: whether to solve your problem with a statistical model that an engineer can explain in a whiteboard session, or with a neural network that requires a GPU cluster and a team of PhDs to interpret. Getting that decision wrong costs millions in infrastructure and months of wasted development.
In 2026, the distinction between deep learning vs. machine learning is no longer academic, it is a strategic business choice that determines project timelines, infrastructure budgets, regulatory compliance, and ultimately whether your AI initiative delivers ROI or becomes a cost center.
Every executive, product manager, and engineer who touches AI infrastructure needs to understand not just what separates these approaches, but when each one wins, why the wrong choice destroys budgets, and how the landscape has shifted dramatically in the past 18 months.
This guide moves beyond the standard “deep learning is a subset of machine learning” explanation you have read a dozen times. We will examine the architectural realities, the 2025 benchmark data that reveals where each approach actually performs, the emerging convergence trends that are blurring the lines, and the decision framework that practitioners at companies like Netflix, Spotify, and OpenAI use to choose between them.
The Hierarchy That Actually Matters: AI, ML, and DL in Context
Most articles start with a Venn diagram showing AI as the largest circle, ML inside it, and DL inside ML. That is technically correct and practically useless.
Here is what actually matters: AI is the business goal. ML is the statistical methodology. DL is neural architecture. When Netflix recommends your next binge, the business layer is AI (personalization), the methodology layer is ML (pattern recognition from historical viewing data), and the architecture layer is a hybrid, collaborative filtering (traditional ML) for ranking, transformer-based deep learning for understanding content semantics.
The hierarchy is not about containment. It is about decision layers:
| Layer | Question It Answers | Example |
| AI | What business problem are we solving? | Reduce customer churn by 15% |
| ML | What statistical approach maps inputs to outputs? | Train on historical churn data to predict probability |
| DL | Do we need neural networks to capture the pattern? | Use transformers to analyze support ticket sentiment as a churn signal |
Understanding this layered decision-making is critical because it prevents the most common mistake in enterprise AI: defaulting to deep learning because it sounds more advanced, then discovering that a random forest would have delivered 94% of the accuracy with 5% of the compute cost.
What Machine Learning Actually Is (And Where It Still Wins)
Machine learning is the discipline of training algorithms to recognize patterns in data without explicit programming for every rule. The learning happens through statistical optimization: the algorithm iteratively adjusts internal parameters to minimize the difference between its predictions and known outcomes.
In 2026, traditional ML remains the workhorse of enterprise AI for one simple reason: most business problems are structured data problems, and structured data problems do not need neural networks.
The ML Algorithms That Still Dominate Enterprise AI
XGBoost and LightGBM: Gradient-boosted decision trees that handle tabular data (spreadsheets, databases, transaction logs) with state-of-the-art accuracy. In Kaggle competitions and production fraud detection systems, these consistently outperform neural networks on structured datasets.
Random Forest: An ensemble of decision trees that trades a small amount of accuracy for massive interpretability gains. When a bank denies a loan, regulators often require the explanation—random forests provide it natively.
Logistic Regression and Linear Models: Surprisingly persistent in production because they are fast, interpretable, and require minimal infrastructure. Credit scoring, marketing attribution, and A/B testing frameworks still rely heavily on these “boring” workhorses.
Support Vector Machines (SVM): Less trendy than in 2010, but still relevant for high-dimensional, smaller datasets where neural networks would overfit.
Where ML Crushes Deep Learning in 2026
Tabular data with fewer than 100,000 rows: Deep learning’s advantage comes from automatic feature extraction at scale. On small-to-medium structured datasets, the overhead of neural architecture design, hyperparameter tuning, and GPU infrastructure outweighs any accuracy gains. A 2025 study comparing traditional ML against transformer-based deep learning on the AG News dataset found that XGBoost and SVM achieved 90.47% and 90.33% accuracy respectively, while a transformer trained from scratch reached only 91%—a marginally better result that required 12x the training time and massive GPU resources.
Regulated industries requiring explainability: Healthcare diagnostics, financial lending, and legal discovery all face “right to explanation” regulations. When a deep learning model rejects a mortgage application, you cannot easily explain *why* to a regulator or a judge. A decision tree or logistic regression can.
Real-time inference on edge devices: A random forest running on a Raspberry Pi can process sensor data in milliseconds. A transformer model of comparable accuracy requires a GPU and hundreds of milliseconds—often unacceptable for autonomous vehicle collision avoidance or industrial safety systems.
Rapid prototyping and iteration: ML models train in minutes on standard CPUs. Deep learning models train in hours or days on GPU clusters. When your product team needs to validate a hypothesis by Friday, ML wins by default.
What Deep Learning Actually Is (And Why It Justifies the Cost)
Deep learning is a subset of machine learning that uses artificial neural networks with multiple hidden layers to learn hierarchical representations directly from raw data. The deep refers to the depth of the network, three or more layers of neurons between input and output.
The critical distinction is automatic feature extraction. Where traditional ML requires human engineers to manually identify and encode relevant features (a process called feature engineering), deep learning models learn features automatically from raw data. This is why a convolutional neural network can identify a cat in a photograph without anyone ever telling it what “fur texture” or “whisker shape” means.
The Neural Architectures Defining 2026
Transformers: The architecture behind GPT-4, Claude, and BERT. Using self-attention mechanisms, transformers process entire sequences in parallel rather than sequentially, capturing long-range dependencies that RNNs and LSTMs miss. They have become the default architecture for natural language processing and are increasingly dominant in computer vision and multimodal AI.
Convolutional Neural Networks (CNNs): Still the standard for image and video analysis. CNNs use convolutional filters to detect local patterns (edges, textures, shapes) and build hierarchical representations from them. Modern vision transformers are challenging CNN dominance, but CNNs remain more efficient for many production vision tasks.
Recurrent Neural Networks (RNNs) and LSTMs: Architectures designed for sequential data (time series, speech, text). While largely superseded by transformers for NLP, RNNs remain relevant for real-time sequence modeling where transformer latency is unacceptable.
Generative Adversarial Networks (GANs) and Diffusion Models: The engines behind generative AI. GANs pit two networks against each other (generator vs. discriminator) to create realistic synthetic data. Diffusion models, used by DALL-E and Midjourney, gradually denoise random data to generate images, videos, and audio.
Where Deep Learning Justifies the Infrastructure Investment
Unstructured data at scale: Images, video, audio, and free text contain patterns that are too complex for manual feature engineering. A 2025 benchmark study found that pre-trained transformer models (RoBERTa, BERT, DistilBERT) achieved 93.66% to 94.54% accuracy on text classification tasks, outperforming the best traditional ML methods (SVM at 90.47%) by 4–7 percentage points. That gap widens dramatically on larger, more complex datasets.
Transfer learning from pre-trained models: This is the game-changer that made deep learning accessible to mid-sized companies. Instead of training a billion-parameter model from scratch, you download a pre-trained foundation model (BERT for text, ResNet for images, Whisper for audio) and fine-tune it on your specific dataset. A 2025 comparative study found that transfer learning with RoBERTa achieved 94.54% accuracy on a news classification task, while the same architecture trained from scratch reached only 91%. The pre-trained model’s knowledge of language structure, learned from billions of documents, transfers directly to your domain.
Multimodal AI: The most exciting frontier in 2026. Multimodal systems process text, images, audio, and sensor data simultaneously using unified transformer architectures. Vision Transformers (ViTs) treat image patches as tokens, enabling seamless integration with text processing. This is the technology behind GPT-4o’s real-time vision and voice capabilities, and it is transforming customer service, content creation, and quality assurance.
Perception and generative tasks: Autonomous vehicles, medical imaging, real-time translation, and synthetic media generation are all deep learning domains. No traditional ML approach comes close to these problems.
Text Classification: Traditional ML vs. Transformers
A 2025 study published in the *International Journal of Computer* compared traditional ML classifiers (Random Forest, XGBoost, Naïve Bayes, SVM) against transformer models on the AG News dataset (120,000 training samples, 4 categories). The results reveal a clear hierarchy:

The critical takeaway: Pre-trained transformers outperform traditional ML by 4–7 percentage points, but only when transfer learning is applied. A transformer trained from scratch barely beats XGBoost and loses to SVM on accuracy, while consuming vastly more resources.
The Performance-Efficiency Trade-off
The same study quantified the resource gap in stark terms. RoBERTa, the most accurate model, required 4,112 seconds of training time. SVM, the best traditional method, required 8,746 seconds, actually slower than RoBERTa in this specific implementation, but running on a standard CPU rather than a GPU cluster. Naïve Bayes trained in 0.2 seconds with 88.95% accuracy, making it viable for applications where speed matters more than marginal accuracy gains.
DistilBERT and ELECTRA emerged as the practical sweet spots. DistilBERT achieved 94.32% accuracy, nearly matching RoBERTa, while cutting training time by over 50%. ELECTRA reached 93.66% accuracy in just 1,103 seconds, making it the most efficient high-performing option for production text classification.
What This Means for Your Budget
If you are classifying support tickets, analyzing survey responses, or routing customer inquiries:
- Budget-constrained, speed-critical: Naïve Bayes or logistic regression (seconds to train, interpretable, CPU-only).
- Balanced performance and cost: XGBoost or LightGBM (minutes to train, excellent accuracy, minimal infrastructure).
- Maximum accuracy, GPU budget available: Fine-tuned DistilBERT or ELECTRA (hours to train, 4–7 point accuracy gain, requires GPU).
The wrong choice is not “deep learning” or “machine learning.” The wrong choice is defaulting to deep learning without calculating whether the accuracy improvement justifies the infrastructure cost.
The Convergence Trend: Why the Distinction Is Blurring in 2026
Here is what most “deep learning vs. machine learning” articles miss entirely: the boundary between these approaches is dissolving in production systems.
Hybrid Architectures Are the New Normal
Netflix and Spotify do not choose between ML and DL. They use both simultaneously in layered recommendation systems:
- Traditional ML handles ranking, A/B testing, and collaborative filtering (structured user behavior data).
- Deep learning models user taste embeddings, content understanding, and cross-modal relationships (unstructured text, images, audio metadata).
The product you experience is a synthesis of both approaches, with each handling the data type it excels at.
Small Language Models (SLMs) and Edge AI
One of the most significant trends reshaping enterprise AI in 2026 is the rise of Small Language Models (SLMs), models ranging from 1 million to 10 billion parameters that deliver transformer-class performance at a fraction of the resource cost.
Leading SLMs in 2026 include:
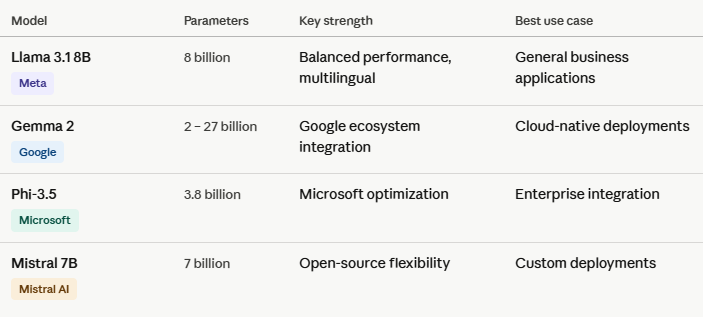
These models run on local devices, smartphones, and edge infrastructure, enabling real-time AI without cloud dependency. The edge AI market was valued at $20.78 billion in 2024 and is growing at 21.7% annually. In 2026, 74% of global data will be processed outside traditional data centers.
What does this mean for the ML vs. DL debate? It means deep learning is becoming as deployable as traditional ML. The infrastructure barrier that once made DL the expensive choice is collapsing. An SLM running on a smartphone can perform tasks that require a server cluster in 2022.
Expert Analysis: When I Choose ML vs. DL in Production
After a decade of building and deploying AI systems across fintech, healthcare, and media, here is my decision framework. It is not theoretical, it is what I use when a product manager asks, “Should we use deep learning for this?”
Choose Traditional Machine Learning When:
- Your data is structured (spreadsheets, databases, transaction logs, sensor readings with clear schema).
- Your dataset has fewer than 100,000 rows or fewer than 1,000 features.
- You need the model to be explainable to regulators, auditors, or business stakeholders.
- You need to iterate rapidly (train, evaluate, and redeploy within hours, not days).
- Your inference environment is constrained (edge devices, CPU-only servers, low-latency requirements).
- You have limited ML engineering resources (XGBoost requires one competent data scientist; a transformer pipeline requires a team).
Choose Deep Learning When:
- Your data is unstructured (images, video, audio, free text, or multimodal combinations).
- Your dataset is large (hundreds of thousands to millions of examples) and the patterns are too complex for manual feature engineering.
- You can leverage transfer learning from a pre-trained foundation model relevant to your domain.
- Accuracy is more important than interpretability (medical imaging, autonomous systems, content generation).
- You have GPU infrastructure or cloud budget for training and inference.
- You have ML engineering expertise to handle the complexity of neural architecture design, distributed training, and model debugging.
Real-World Applications: Where Each Approach Delivers in 2026
Machine Learning Dominates:
- Fraud detection: Banks use XGBoost and random forests to analyze transaction patterns in real time. The models are interpretable, fast, and retrainable daily.
- Credit scoring: Logistic regression and gradient-boosted trees remain the standard because regulators require explanation of denial decisions.
- Demand forecasting: Retailers and manufacturers use ARIMA, Prophet, and LightGBM to predict inventory needs from historical sales data.
- Predictive maintenance: Industrial IoT sensors feed structured vibration, temperature, and pressure data into ML models that predict equipment failure before it occurs.
Deep Learning Dominates:
- Medical imaging: CNNs and vision transformers detect tumors, fractures, and retinal diseases in radiology scans with accuracy exceeding human specialists in some domains.
- Autonomous vehicles: Multimodal deep learning fuses camera, LiDAR, and radar data to perceive and navigate complex environments.
- Real-time translation and speech recognition: Transformer-based models power the simultaneous translation and voice interfaces in products like GPT-4o and Google Translate.
- Generative AI: Diffusion models and GANs create synthetic media, design assets, and training data for other AI systems.
- Multimodal customer service: AI agents that understand voice tone, facial expressions, and text context to provide empathetic, effective support.
FAQs: Deep Learning vs. Machine Learning
Is deep learning always more accurate than machine learning?
No. On structured, tabular datasets with fewer than 100,000 rows, traditional ML methods like XGBoost and SVM often match or exceed deep learning accuracy while training orders of magnitude faster. Deep learning’s advantage emerges on large, unstructured datasets where automatic feature extraction matters. A 2025 benchmark found XGBoost at 90.33% accuracy versus a scratch-trained transformer at 91% on the same text dataset, essentially equivalent, with the transformer requiring 12x the training time.
Can I use deep learning for small datasets?
Technically yes, practically no. Deep learning models have millions to billions of parameters. Without sufficient data, they overfit—memorizing the training set rather than learning generalizable patterns. A rule of thumb: deep learning becomes viable when you have thousands of examples per feature, or when you can use transfer learning from a pre-trained model. For small datasets, traditional ML with regularization is more reliable.
Why is deep learning called a “black box”?
Traditional ML models like decision trees and logistic regression produce human-interpretable rules or coefficients. You can trace exactly why a loan was denied. Deep learning models distribute learning across millions of parameters in hidden layers. While techniques like attention visualization and SHAP values provide partial explanations, the full reasoning process remains opaque. This is why regulated industries often prefer ML for high-stakes decisions.
Do I need a GPU for machine learning?
No. Traditional ML algorithms run efficiently on CPUs. You need GPUs for deep learning because matrix operations across millions of parameters are massively parallelizable, and GPUs excel at parallel computation. However, with the rise of Small Language Models and edge AI in 2026, some deep learning workloads are becoming CPU-viable again.
Which should I learn first: machine learning or deep learning?
Start with machine learning. Deep learning builds on ML fundamentals, loss functions, gradient descent, train/validation/test splits, overfitting, and regularization. Mastering these concepts with simpler models (linear regression, decision trees) makes the leap to neural networks intellectually manageable. Additionally, ML skills are more immediately applicable in enterprise environments where structured data dominates.
Conclusion: The Pragmatism of Choosing Correctly
The deep learning vs. machine learning debate is not a contest with a winner. It is a toolbox with two categories of tools, and the professionals who thrive in 2026 are those who know which to reach for, and why.
Deep learning has earned its hype. Transformers, CNNs, and generative models have achieved capabilities that seemed impossible five years ago. But that capability comes with real costs: infrastructure, expertise, opacity, and time. Machine learning, meanwhile, remains the unsung workhorse of enterprise AI, solving structured data problems with speed, interpretability, and minimal resource requirements.
The convergence trends of 2026, Small Language Models, edge AI, AutoML, and hybrid architectures, are making the boundary less rigid. But they are not eliminating the need for informed choice. They are raising the stakes of that choice, because the wrong decision now wastes more resources than ever before.
My final advice: start with the problem, not the technology. Define what you are trying to predict, perceive, or generate. Audit your data type, volume, and structure. Calculate your accuracy requirements, explainability constraints, and infrastructure budget. Then, and only then, choose between the statistical elegance of a gradient-boosted tree and the neural power of a transformer. The right choice is the one that solves your problem within your constraints. Everything else is vanity.












{kind=link}